
Docker Swarm integration in version 1.12 changed the creation of a Docker cluster from an installation hell to a 5 minute operation. However while many things such as network are great in Swarmkit, the most prominently missing feature is the data distribution. As Docker acquired Infinit last year we can expect something in near future but at the moment batteries are yet to be included…
Existing solutions
For quite a long time I have a pet project of a swarm cluster and the weak spot was definitely the distribution of the volumes. There are many volume plugins available and removing the plugins requiring a cloud storage or a complicated backend (i.e. to complex to install in small cluster) lead me to a small short list:
All of these plugins were working OK but have at least a super serious flaw that prevented me to choose them:
- Flocker, at the time of my test, required ZFS and an ssh root access between the servers to move the data between servers (and now ClusterhQ, the company behind Flocker has been shut down).
- While GlusterFS itself was working great, the Docker plugin was outdated (now unmaintened) and the volume creation from Docker required an even more outdated component.
- Infinit demo was really great but was relying on a patched version of Docker.
Here Comes Convoy
To summarize, at this point I have a working Docker cluster and a distributed storage using GlusterFS: the only missing part was a volume plugin. In my first plugin test, I didn’t consider Convoy since I only saw NFS and device mapper in the supported backends. Recently I noticed that the NFS driver was not doing any NFS operation but relying on a remote NFS volume to be mounted locally. So I could easily swap NFS with something loaded with hype such as my working GlusterFS storage.
Installation
At the time of this writing, Convoy only supports the legacy plugin system which involves an installation a little bit more complicated. However, while Convoy does not come packaged for any distribution it’s a static binary so the installation is pretty simple:
wget https://github.com/rancher/convoy/releases/download/v0.5.0/convoy.tar.gz
tar -xvzf convoy.tar.gz
sudo cp convoy/convoy convoy/convoy-pdata_tools /usr/local/bin/Then setup a communication socket between Docker and Convoy:
sudo mkdir -p /etc/docker/plugins/
sudo bash -c 'echo "unix:///var/run/convoy/convoy.sock" > /etc/docker/plugins/convoy.spec'The next step is to start Convoy and for this we need a specific directory on the distributed file system for instance: /shared/volumes/convoy. Convoy could then be started:
sudo convoy daemon --drivers vfs --driver-opts vfs.path=/shared/volumes/convoyYou can then test the volume create either with the convoy command or with docker:
# Create with Convoy
sudo convoy create test_volume
# Create a volume explicitly
docker volume ls docker volume create -d convoy test_volume
# Create a volume on the fly
docker run -it -v test_volume:/test --volume-driver=convoy debianBehind the scene when a volume is created, Convoy will create a directory with volume name in <vfs.path>. It also creates a <vfs.path>/config directory to store data on the existing volumes.
Next step is to install and configure Convoy on the other nodes of the cluster. As Convoy works relatively from <vfs.path> the distributed volume does not need to me mounted in the same location on all nodes but in my opinion it’ll add some unnecessary complexity to the setup. When the daemons are started you can perform a test like the one below (with a nice clock synchronization issue on one of the nodes):
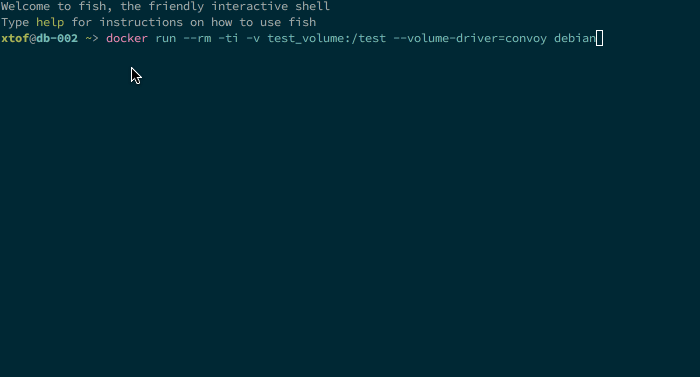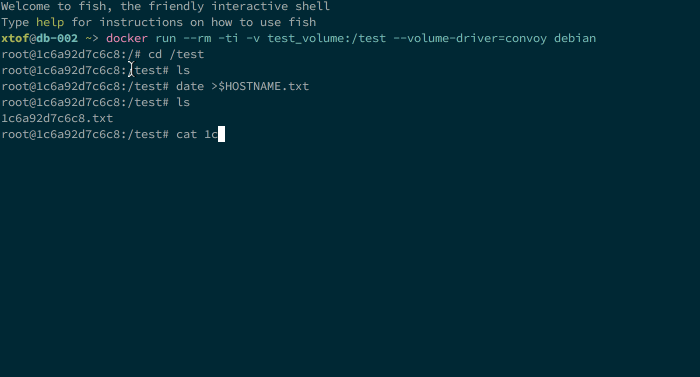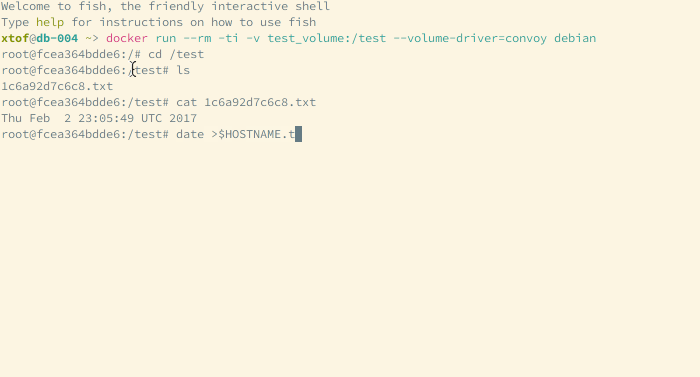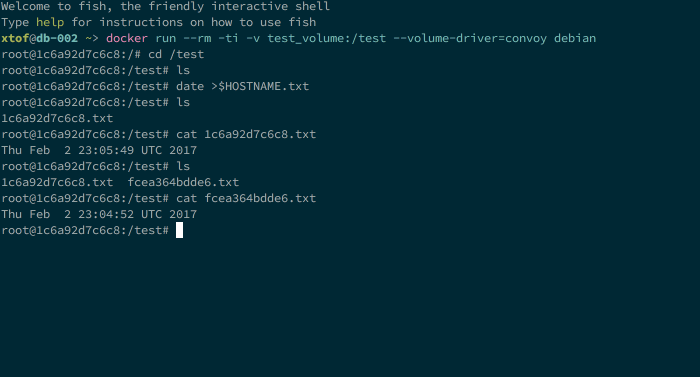
So far I only came on two issues:
When deleting a volume from Docker, the storage directory is not deleted which means that if you create later a volume with the same name, the previous contents will still be there. The problem does not arise if the volume is deleted using convoy delete which also has an option to only remove the volume reference keeping the contents.
While all the volume operations are propagated there are still some holes. For instance on a two node cluster:
- You create on both nodes a container referencing the same convoy volume and stop them (but do not delete them)
- On node one, you delete the container and the volume
- On node two, you can see that the volume has been deleted but if you want to recreate a volume with the same name you’ll get a rather cryptic error message about references to volume with the same name
This is happening because the volume was deleted from node one without checking that a container on node two was still referencing the volume. Delete the container and everything will be working fine
Starting up on Boot
You can easily use systemd you have convoy start when booting your server. For my part I’m using this simple unit:
After putting this file in /etc/systemd/system you can enable it with the following commands:
systemctl daemon-reload
systemctl enable convoy.serviceConclusion
I noticed that Convoy provides a glusterfs plugin which is not advertised in the documentation. After reading the source code I didn’t find any difference significant enough to switch from my current configuration. Also I didn’t find any plugin implementation relying on the new API.
However to be short: Convoy is a very clever hack to solve a huge pain in the butt of the current clustering implementation. As Convoy is relying on a third party system to make the actual storage of data it should be as trustable as the underlying storage system. I’m sure Docker will come with a cool distributed volume system following the acquisition of Infinit in a forthcoming version but in the meantime, Convoy is a great way to overcome one of the biggest the current Swarmkit limitations.