
Spring Data is a nice system to create repository without having to write a single line of code beyond an interface declaration. What’s extra-nice is that Spring Data can work with different underlying persistence systems like JPA or MongoDB. I know Spring Data JPA to be quite effective but since RDMBS and Mongo DB are really different I wanted to see how Spring Data behaved with Mongo DB.
Being Amazon.com
I started with a simple scenario: an e-commerce site with reviews associated with the items. In a relational database I would have a table for the items and a table for the review, each review being one row in this last table. In MongoDB one implementation would be to store the review in the item document. In a real world a bucketing system will probably be implemented but I’ll stick to this naive implementation for the purpose of the test.
Scenario
Since my site is very popular, I will need to add up to 4000 reviews on my item (this is consistent with what you can have on a popular item on Amazon). The scenario will be:
- Create a new item
- Insert 4000 reviews to the item, saving the item to the database after adding each review.
In order to check how Spring Data is behaving I’ll run two implementations of the scenario using one of the following methods to save the reviews:
Implementation
Data Classes
Item.java
@Document
public class Item {
@Id
private String id;
private String name;
private String description;
private List<Comment> comments = new ArrayList<>();
}Comment.java
public class Comment {
private String customer;
private String comment;
}ItemRepository.java
There will be no special method in the repository as we will only use the basic findOne and save.
public interface ItemRepository extends MongoRepository<Item, String> {}Test Code
Spring Data Repository
In this implementation everything is done on the Java structure and Spring Data will be in charge of handling the gory details. This implementation is really simple and is (probably) compatible with any of the underlying storage supported by Spring Data.
Item item = repository.save(new Item().name("Twilight").description("Blu ray special edition"));
for (int i = 0; i < 40; i++) {
Stopwatch stopwatch = Stopwatch.createStarted();
for (int j = 0; j < 100; j++) {
item.comments().add(new Comment().customer("Customer " + i + ":" + j)
.comment(Strings.repeat(String.valueOf(i * 100 + j), j)));
repository.save(item);
}
stopwatch.stop();
System.err.println("Repo " + (i + 1) + ": " + stopwatch.elapsed(TimeUnit.MILLISECONDS));
}Mongo Operations
This implementation will use the low level MongoOperations interface. The Java code will mimic what would have been done in the Mongo Shell:
db.item.update(
{ _id: ObjectId("objectId")},
{ $push: { comments: { customer: "Customer", comment: "The comment"}}}
)Compared to the previous version this implementation is completely specific to MongoDB.
item = repository.save(new Item().name("The Fellowship of the ring").description("Blu ray special edition"));
for (int i = 0; i < 40; i++) {
Stopwatch stopwatch = Stopwatch.createStarted();
for (int j = 0; j < 100; j++) {
operations.updateFirst(
new Query(where("_id").is(item.id())),
new Update().push("comments",
new Comment().customer("Customer " + i + ":" + j)
.comment(Strings.repeat(String.valueOf(i * 100 + j), j))),
Item.class
);
repository.save(item);
}
stopwatch.stop();
System.err.println("Ops " + (i + 1) + ": " + stopwatch.elapsed(TimeUnit.MILLISECONDS));
}Results
I ran the test on my laptop using a database running locally. The Spring Data implementation took more that one minute to run while the Mongo Operations implementation did finish in less than 3 seconds.
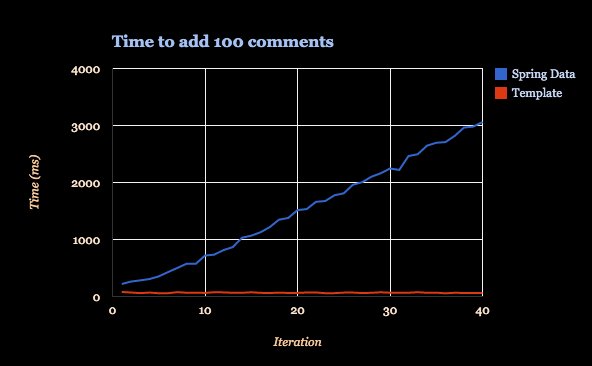
As the time to update the document is roughly proportional to the document size it seems that Spring Data is sending the complete object to MongoDB each time an update is required. On a remote database, the results will be also impacted by the network speed. On the other end, the low level implementation has a constant response time regardless of the number of reviews in the item.
Conclusion
As I wrote above, the scenario is a little bit naive to be a real world scenario. However it shows that MongoDB is actually quite efficient to push new information at the end of an array and also that operations with Spring Data can be suboptimal when dealing with large and complex documents. That does not mean that Spring Data Mongo should not be used but you have to be extra-careful with it and in some cases use some low level API (Jongo is a pretty nice one) to take advantage of all MongoDB features.